Dieser Artikel ist keine Rechtsberatung. Er soll Akademien, Bildungsanbieter und Unternehmen helfen, den technischen und rechtlichen Prozess besser zu verstehen. Ob ein konkretes System zulässig ist, hängt immer von der konkreten Umsetzung ab: Nutzerkreis, technische Architektur, Zweck, Ausgabegrenzen, Löschmechanismus, Datenschutz und Art des verwendeten Materials.
Wenn du heute hier bist, hast du wahrscheinlich keine theoretische Frage. Du hast ein echtes Prozessproblem.
Du hast ein Fachbuch gekauft. Vielleicht ein IHK-Lehrbuch, ein Prüfungsvorbereitungsbuch, ein technisches Handbuch oder ein internes Schulungsdokument. Genau dieses Dokument enthält das Wissen, das deine Teilnehmer brauchen. Also entsteht im Kopf sofort dieser einfache Ablauf:
Dokument kaufen → Dokument hochladen → Dokument mit Teilnehmern teilen.
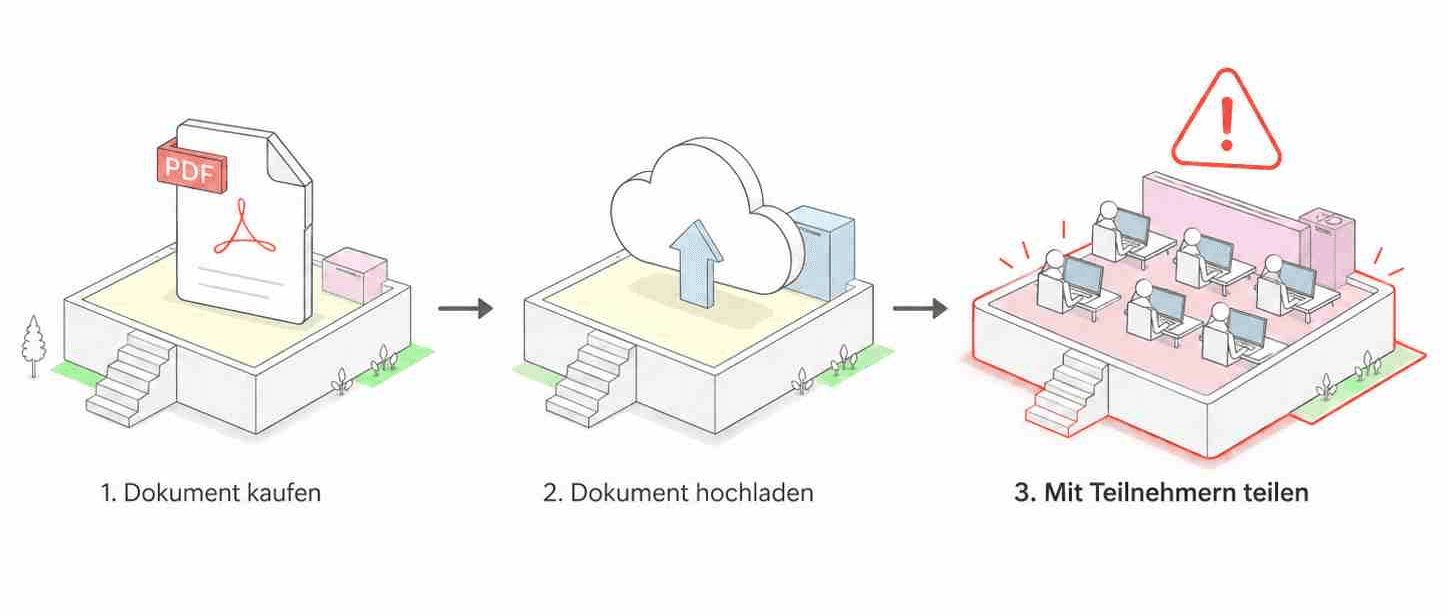
Dieser Prozess ist verständlich. Aber er ist nicht der Prozess, den man bauen sollte.
Denn sobald Teilnehmer das vollständige PDF, E-Book oder Lehrbuch selbst öffnen, herunterladen, kopieren oder dauerhaft lesen können, sieht das nicht mehr nur nach Lernen aus. Es sieht nach Weitergabe des Werkes aus. Urheberrechtlich können dabei insbesondere das Vervielfältigungsrecht und die öffentliche Zugänglichmachung betroffen sein: § 16 UrhG beschreibt das Recht, Vervielfältigungsstücke eines Werkes herzustellen; § 19a UrhG betrifft das Zugänglichmachen eines Werkes für Mitglieder der Öffentlichkeit von Orten und zu Zeiten ihrer Wahl.
Der bessere Prozess beginnt deshalb mit einer anderen Frage.
Nicht:
Wie geben wir das Buch an alle weiter?
Sondern:
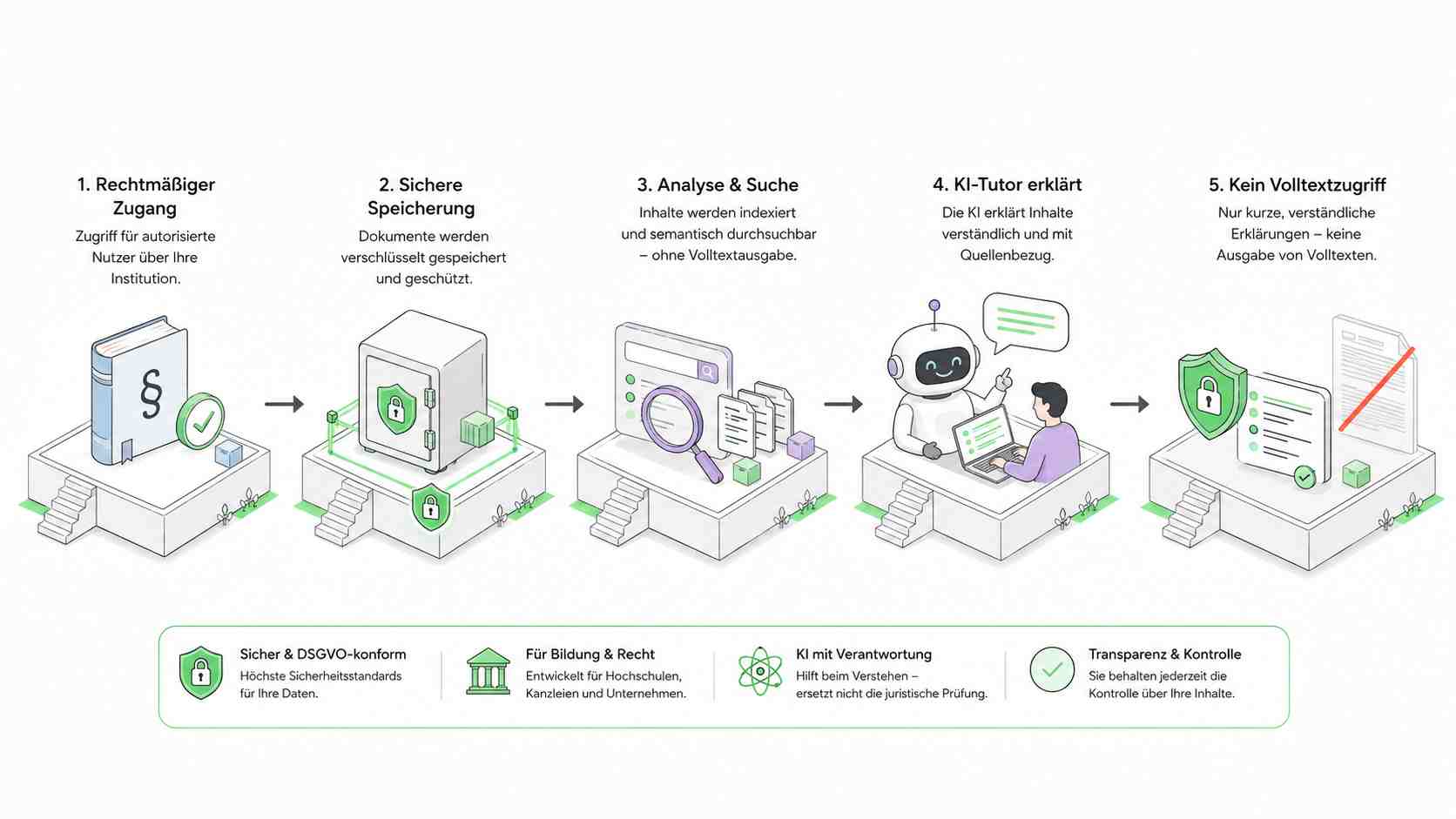
Wie kann ein rechtmäßig zugängliches Dokument intern genutzt werden, damit Teilnehmer Fragen stellen und Erklärungen erhalten, ohne das Dokument selbst zu bekommen?
Damit ändert sich alles.
Aus:
Kaufen → Hochladen → Teilen
wird:
Rechtmäßiger Zugang → geschützte Verarbeitung → Suche → Analyse → Erklärung → Originaltext bleibt geschützt.
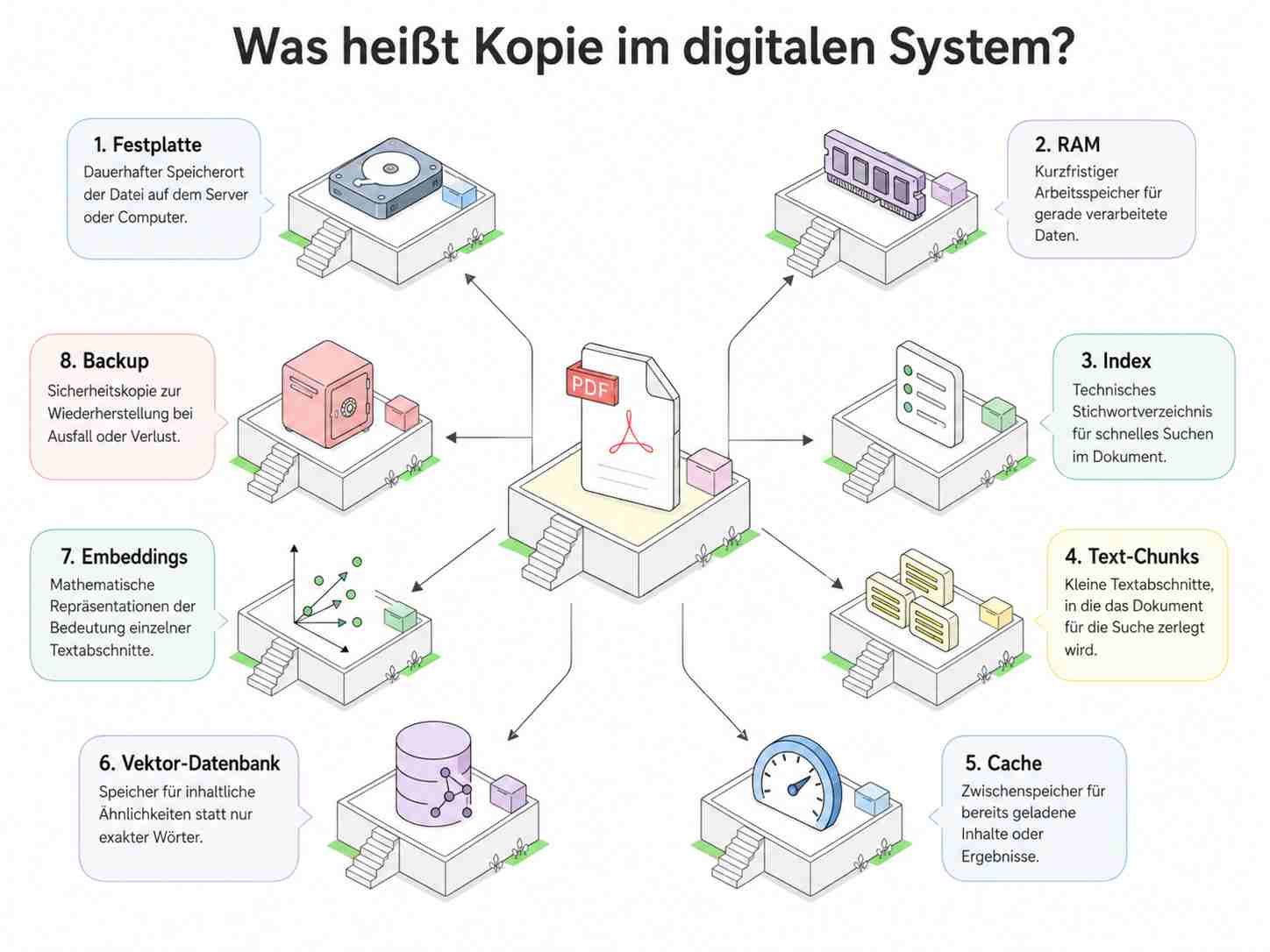
Jetzt kommt der Teil, den viele falsch verstehen: Was heißt eigentlich „Kopie“ in einem digitalen System? Viele denken bei „Kopie“ an: Jemand kopiert eine PDF-Datei und schickt sie an andere. Das ist eine Kopie, ja. Aber in digitalen Systemen entstehen auch viele technische Kopien, ohne dass jemand das Dokument wie ein Buch verteilt.
Die Datei liegt zuerst auf einer Festplatte. Das ist der dauerhafte Speicher eines Computers oder Servers. Dort bleibt die Datei auch dann erhalten, wenn das Gerät ausgeschaltet wird.
Beim Öffnen landet ein Teil der Datei im RAM. RAM bedeutet Arbeitsspeicher. Das ist der schnelle Kurzzeitspeicher, mit dem ein Computer gerade aktive Daten verarbeitet. Wenn das System neu startet, ist dieser Speicher normalerweise wieder leer.
Beim Durchsuchen entsteht oft ein Index. Ein Index ist wie das Stichwortverzeichnis am Ende eines Buches, nur technisch. Das System merkt sich, welche Begriffe oder Textstellen wo vorkommen, damit es später schneller suchen kann.
Bei modernen KI-Suchsystemen entstehen oft Text-Chunks. Ein Chunk ist ein kleiner Abschnitt des Dokuments, zum Beispiel ein Absatz oder mehrere Sätze. Das System zerlegt das Dokument in solche Stücke, damit es bei einer Frage nicht jedes Mal das komplette Buch verarbeiten muss.
Manchmal entstehen Cache-Dateien. Cache bedeutet Zwischenspeicher. Das System merkt sich kurzfristig bereits geladene Inhalte oder Suchergebnisse, damit es schneller antworten kann.
In einer Vektor-Datenbank werden Inhalte als mathematische Bedeutungsräume gespeichert. Das System sucht dann nicht nur nach exakt demselben Wort, sondern erkennt auch inhaltliche Nähe. Wenn jemand „Kostenverhalten“ fragt, kann das System zum Beispiel auch relevante Stellen zu „fixen und variablen Kosten“ finden.
Diese mathematischen Repräsentationen heißen Embeddings. Ein Embedding ist keine normal lesbare Buchseite, sondern eine Zahlenreihe, die die Bedeutung eines Textabschnitts technisch abbildet. Trotzdem gehört auch das in ein Schutz- und Löschkonzept, weil es aus einem konkreten Dokument erzeugt wurde.
Und dann gibt es Backups. Ein Backup ist eine Sicherheitskopie, damit Daten nach einem Ausfall wiederhergestellt werden können. Auch Backups sind Kopien und sollten deshalb nicht vergessen werden.
Der Punkt ist einfach: Digitale Nutzung ohne technische Kopien ist praktisch kaum möglich. Ein Dokument kann nicht angezeigt, durchsucht, gecacht oder analysiert werden, ohne dass Daten verarbeitet werden.
Das Urheberrecht kennt diese Realität. § 44a UrhG erlaubt vorübergehende Vervielfältigungen, wenn sie flüchtig oder begleitend sind, integraler und wesentlicher Teil eines technischen Verfahrens sind, eine rechtmäßige Nutzung ermöglichen und keine eigenständige wirtschaftliche Bedeutung haben. Das passt besonders zu RAM, Cache und technischen Zwischenprozessen.
Für die automatisierte Analyse ist § 44b UrhG zentral. Dort wird Text und Data Mining als automatisierte Analyse digitaler oder digitalisierter Werke beschrieben, um daraus Informationen zu gewinnen. § 44b erlaubt Vervielfältigungen rechtmäßig zugänglicher Werke für Text und Data Mining; diese Vervielfältigungen sind zu löschen, wenn sie dafür nicht mehr erforderlich sind, und die Nutzung ist ausgeschlossen, wenn ein wirksamer Nutzungsvorbehalt besteht. Bei online zugänglichen Werken muss ein solcher Vorbehalt maschinenlesbar sein.
Das bedeutet praktisch:
Die technische Kopie ist nicht automatisch eine verbotene Weitergabe. Entscheidend ist, wofür sie entsteht, wer Zugriff bekommt, was ausgegeben wird und ob das Originalwerk geschützt bleibt.
Jetzt kommt der KI-Tutor.
Ein Teilnehmer soll nicht das Buch bekommen. Er soll eine Frage stellen können.
Nicht:
„Zeig mir Seite 48.“
Nicht:
„Kopiere mir Kapitel 3.“
Nicht:
„Gib mir alle Aufgaben aus dem Buch.“
Sondern zum Beispiel:
„Ich habe eine Aufgabe zu fixen und variablen Kosten. In der Aufgabe kommen Miete, Materialverbrauch und Produktionsmenge vor. Ich verstehe nicht, woran ich erkenne, welche Kostenart gemeint ist. Kannst du mir den Denkweg erklären, den ich in der Prüfung anwenden soll?“
Jetzt ist klar, was gemeint ist. Der Teilnehmer will nicht die Originalaufgabe aus dem Buch kopieren. Er will verstehen, wie er eine solche Aufgabe lösen soll.
Eine gute Antwort wäre dann:
„In solchen Aufgaben prüfst du zuerst, ob sich der Kostenbetrag verändert, wenn sich die Produktionsmenge verändert. Bleibt der Betrag gleich, spricht das für fixe Kosten, zum Beispiel Miete. Verändert sich der Betrag mit der Menge, spricht das für variable Kosten, zum Beispiel Materialverbrauch. Der wichtige Prüfungsgedanke ist also nicht der Name der Kostenposition, sondern ihr Verhalten bei veränderter Beschäftigung.“
Das ist keine Ausgabe des Buches. Das ist eine eigenständige Erklärung.
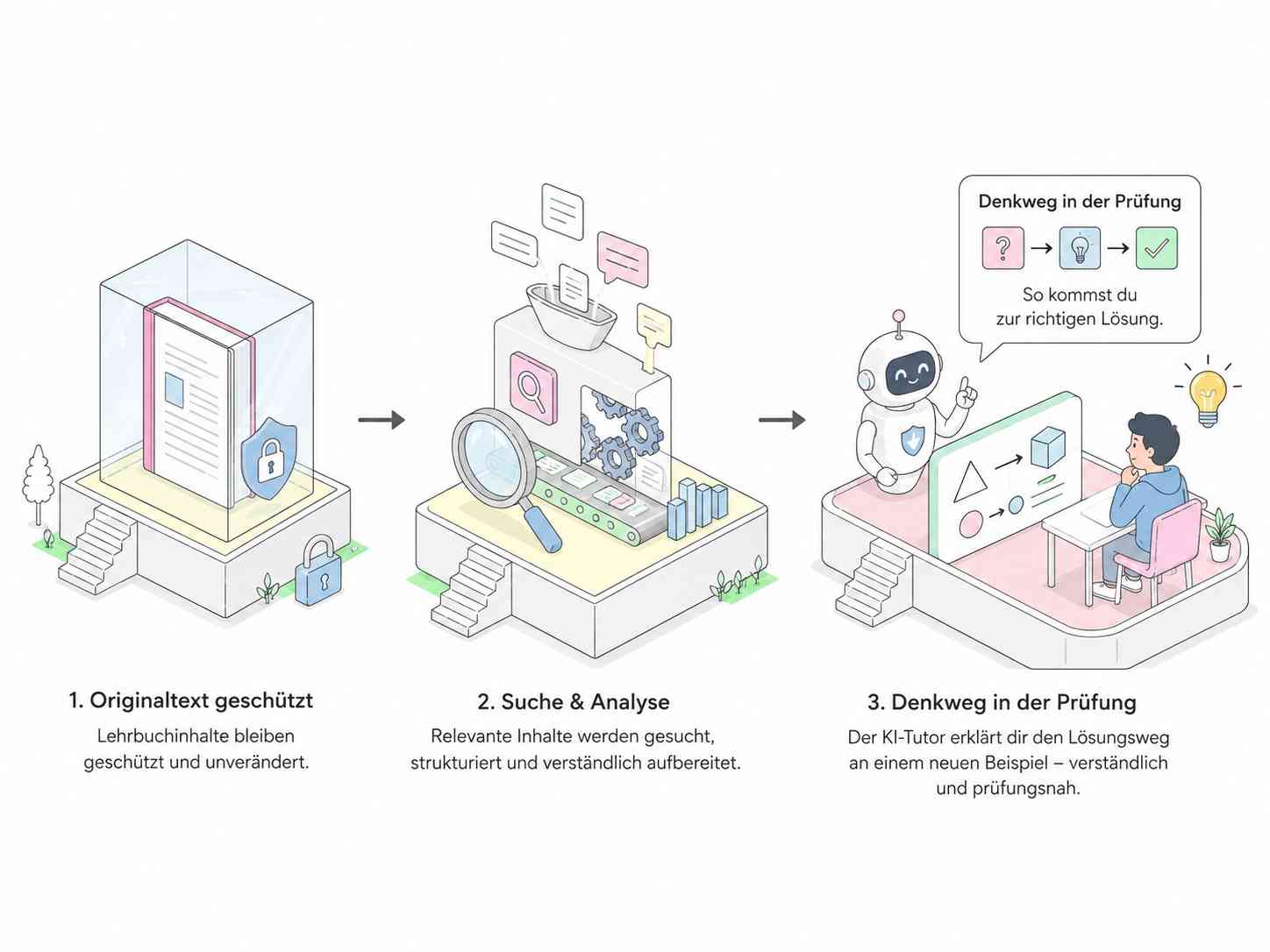
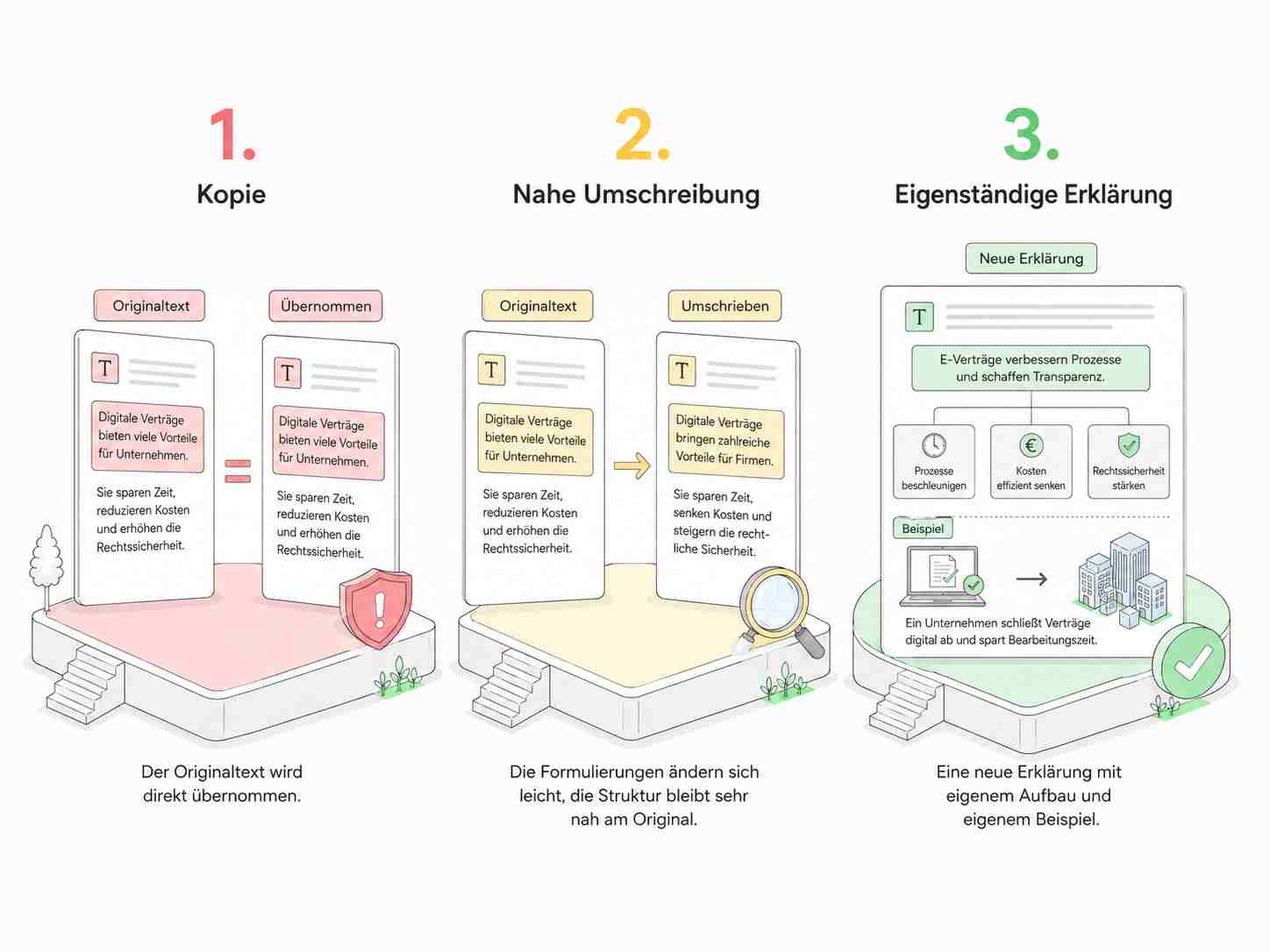
Genau hier liegt der Kern der Architektur.
Ein Mensch darf ein Buch lesen, verstehen und danach frei unterrichten. Er darf aber nicht einfach das Buch abschreiben, Aufgabenbanken kopieren, Tabellen übernehmen oder das Werk so nachbauen, dass der Kauf des Originals überflüssig wird.
Beim KI-Tutor ist der Gedanke ähnlich, nur technisch anspruchsvoller. Die Maschine braucht technische Verarbeitungsschritte, um suchen und analysieren zu können. Diese Schritte müssen über § 44a und § 44b UrhG sauber eingeordnet werden. Die Antwort selbst muss dann eine eigene Erklärung sein und darf nicht die geschützte Gestaltung des Buches übernehmen.
Deshalb sollte man nicht mit Etiketten arbeiten wie „Derivat“ oder „keine Kopie“. Entscheidend ist nicht das Wort, sondern die tatsächliche Nutzung.
Wird die konkrete Ausdrucksform übernommen, also Formulierungen, Tabellen, Aufgaben, Grafiken, besondere Beispiele oder eine prägende didaktische Struktur, entsteht Risiko.
Wird dagegen Wissen verarbeitet und daraus eine eigenständige Erklärung mit eigenem Aufbau, eigenen Beispielen und hinreichendem Abstand formuliert, ist die Situation eine andere. § 23 UrhG stellt bei Bearbeitungen und Umgestaltungen gerade auf diesen Abstand ab: Wenn ein neues Werk hinreichenden Abstand zum benutzten Werk wahrt, liegt keine Bearbeitung oder Umgestaltung im Sinne dieser Vorschrift vor.
Auch das Thema KI-Training sollte sauber getrennt werden.
In diesem Prozess geht es nicht darum, ein neues allgemeines Sprachmodell mit fremden Lehrbüchern zu trainieren. Das wäre eine andere, härtere Debatte. In der Rechtswissenschaft gibt es ernstzunehmende Stimmen, etwa Tim W. Dornis und Sebastian Stober, die argumentieren, dass generatives KI-Training nicht ohne Weiteres unter klassisches Text und Data Mining fallen sollte, weil generative Modelle nicht nur semantische Informationen, sondern auch syntaktische Muster und Ausdrucksformen verarbeiten können.
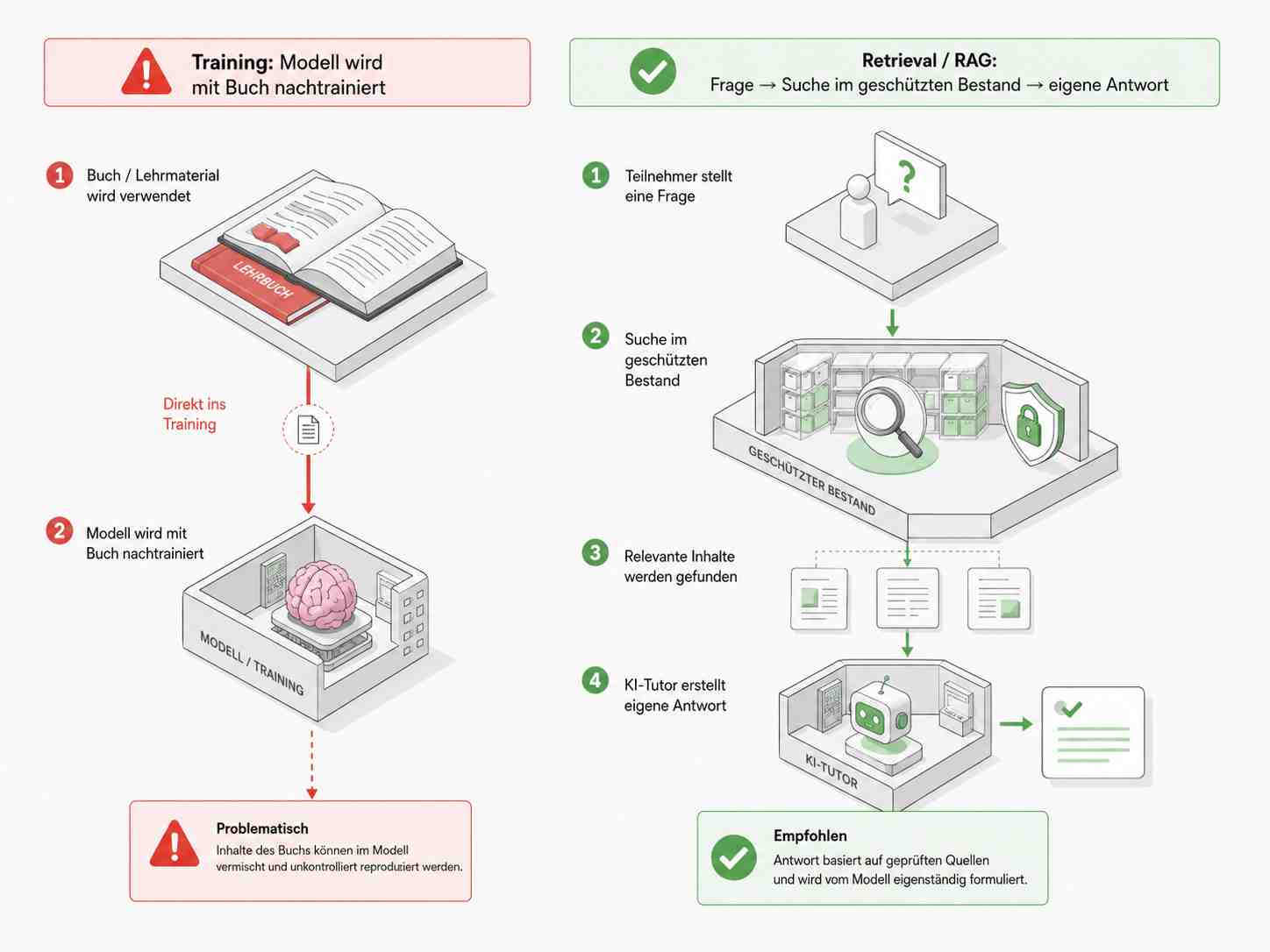
Der professionellere Akademie-Prozess sieht anders aus:
Das Modell wird nicht auf dem Buch nachtrainiert. Das Buch bleibt in einem geschützten Wissensspeicher. Der Assistent sucht bei einer konkreten Frage relevante Stellen, nutzt sie zur Orientierung und formuliert eine eigene Antwort.
Das nennt man häufig Retrieval oder RAG.
Retrieval bedeutet Abruf. Das System sucht passende Informationen in einem vorhandenen Wissensbestand.
RAG bedeutet Retrieval-Augmented Generation. Auf Deutsch: Die Antwortgenerierung wird durch eine Suche in zugelassenen Quellen unterstützt. Das Modell „lernt“ das Buch nicht dauerhaft wie beim Training, sondern schlägt für eine konkrete Frage in einem geschützten Bestand nach.
Jetzt wird es besonders praktisch: Was passiert mit Grafiken, Tabellen, Diagrammen und Abbildungen?
Viele Lehrbücher erklären Inhalte nicht nur über Text. Sie enthalten Schaubilder, Prozessgrafiken, Bilanzschemata, Kostenverläufe, Prüfungsmatrizen oder didaktische Abbildungen. Ein KI-Tutor muss manchmal gerade diese Darstellung erkennen, auswerten und erklären können.
Beispiel:
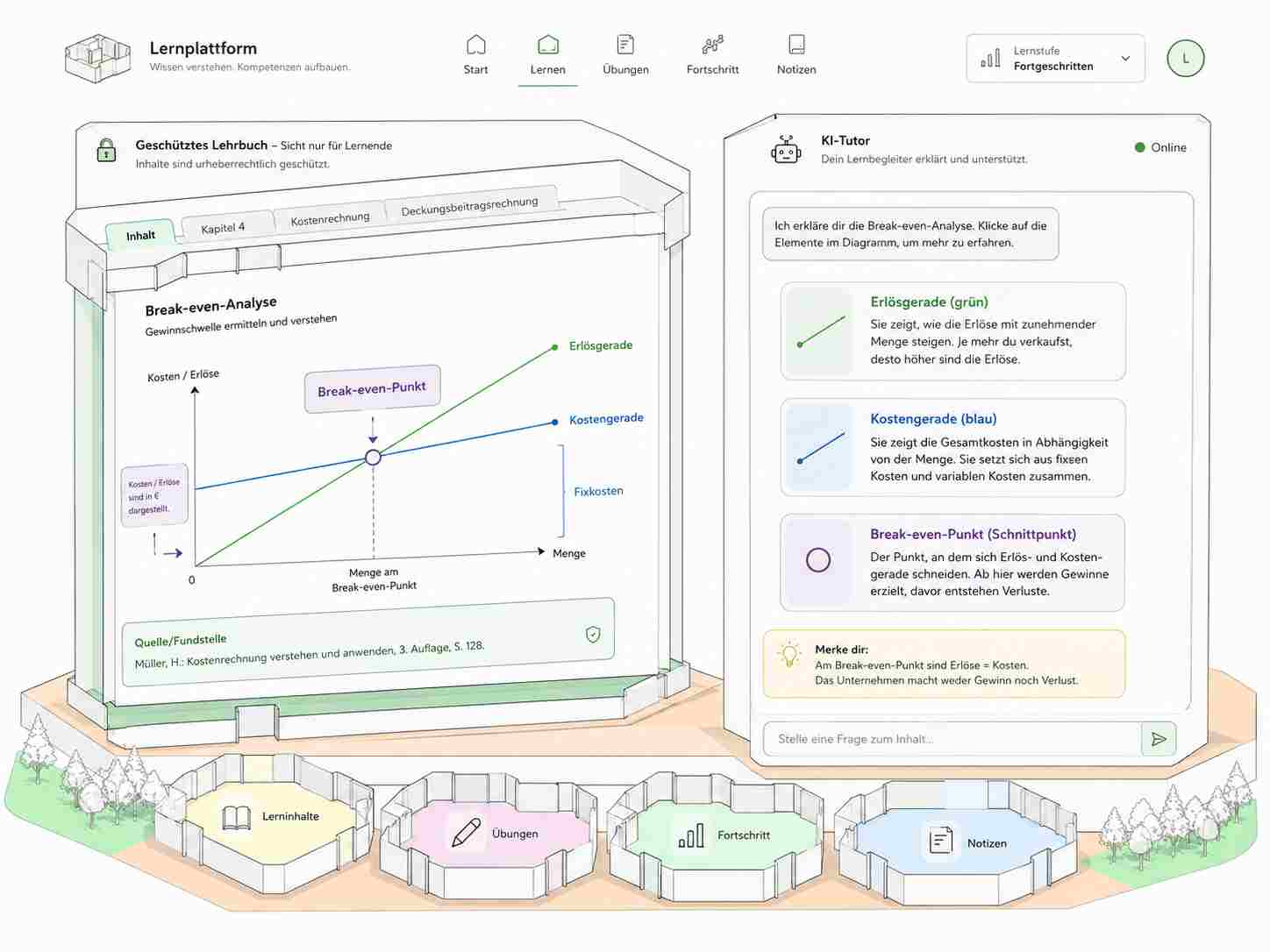
Ein Teilnehmer sieht im Lernsystem ein Break-even-Diagramm und fragt:
„Ich verstehe diese Grafik nicht. Warum schneiden sich die Linien genau an dieser Stelle, und warum ist dieser Punkt prüfungsrelevant?“
In so einem Fall ist die Grafik nicht Dekoration. Sie ist der Gegenstand der Frage. Der Tutor muss erklären können, was die Achsen bedeuten, welche Linie die Kosten zeigt, welche Linie den Umsatz zeigt, warum der Schnittpunkt entsteht und welcher Denkfehler in Prüfungen häufig passiert.
Hier muss man sauber unterscheiden: Analyse der Grafik und Anzeige der Grafik sind nicht dasselbe.
Die automatisierte Analyse einer Grafik kann in den Bereich des Text und Data Mining fallen, weil § 44b UrhG auf digitale oder digitalisierte Werke abstellt und nicht nur auf Fließtext im Alltagssinn. Dass auch Bilder in diesem Kontext eine Rolle spielen können, zeigt der Hamburger LAION-Komplex: Das OLG Hamburg entschied am 10. Dezember 2025, dass sich der Beklagte hinsichtlich der Nutzung einer heruntergeladenen Fotografie auf § 44b UrhG berufen könne; der dortige Nutzungsvorbehalt war nach Auffassung des Gerichts nicht in der gesetzlich vorgesehenen maschinenlesbaren Form erfolgt. Die Entscheidung ist nicht rechtskräftig, weil Revision zugelassen wurde.
Das bedeutet für den KI-Tutor: Eine Grafik maschinell zu erkennen, zu durchsuchen, semantisch einzuordnen oder für eine Antwort zu analysieren, ist zunächst ein Analysevorgang. Sobald die Grafik aber dem Teilnehmer angezeigt wird, passiert zusätzlich eine Wiedergabe eines fremden Werkteils. Dafür braucht man eine eigene Begründung.
Die erste wichtige Grundlage ist das Zitatrecht nach § 51 UrhG. § 51 erlaubt die Vervielfältigung, Verbreitung und öffentliche Wiedergabe eines veröffentlichten Werkes zum Zweck des Zitats, sofern die Nutzung in ihrem Umfang durch den besonderen Zweck gerechtfertigt ist. Die Universität Bremen erläutert dazu ausdrücklich, dass auch Bildzitate möglich sind und fremde geschützte Bilder in eigene Lehrmaterialien eingebunden werden können, wenn die Voraussetzungen erfüllt sind. Wichtig ist der Zitatzweck: Das Bild darf nicht nur Schmuck sein und nicht eigene Ausführungen ersetzen. Es muss inhaltlich gebraucht werden.
Für einen KI-Tutor heißt das praktisch:
Eine Grafik darf nicht einfach als „Bild aus dem Buch“ angezeigt werden.
Sie sollte nur dann gezeigt werden, wenn sie für die konkrete Erklärung erforderlich ist.
Nicht:
„Hier ist eine schöne Grafik aus dem Buch.“
Sondern:
„Hier ist genau die Grafik, auf die sich deine Frage bezieht. Ich erkläre dir anhand der markierten Linien, warum der Schnittpunkt den Break-even-Point zeigt.“
Die zweite wichtige Grundlage kann § 60a UrhG sein, also die Nutzung zur Veranschaulichung von Unterricht und Lehre. § 60a erlaubt unter bestimmten Voraussetzungen Nutzungen veröffentlichter Werke für Unterricht und Lehre; Abbildungen dürfen nach § 60a Abs. 2 vollständig genutzt werden. Die Vorschrift ist aber an den Unterrichtskontext, den bestimmten Teilnehmerkreis und den nicht-kommerziellen Zweck gebunden.
Daraus folgt kein „Grafiken immer anzeigen“. Es folgt ein praktischer, didaktischer Prüfprozess:
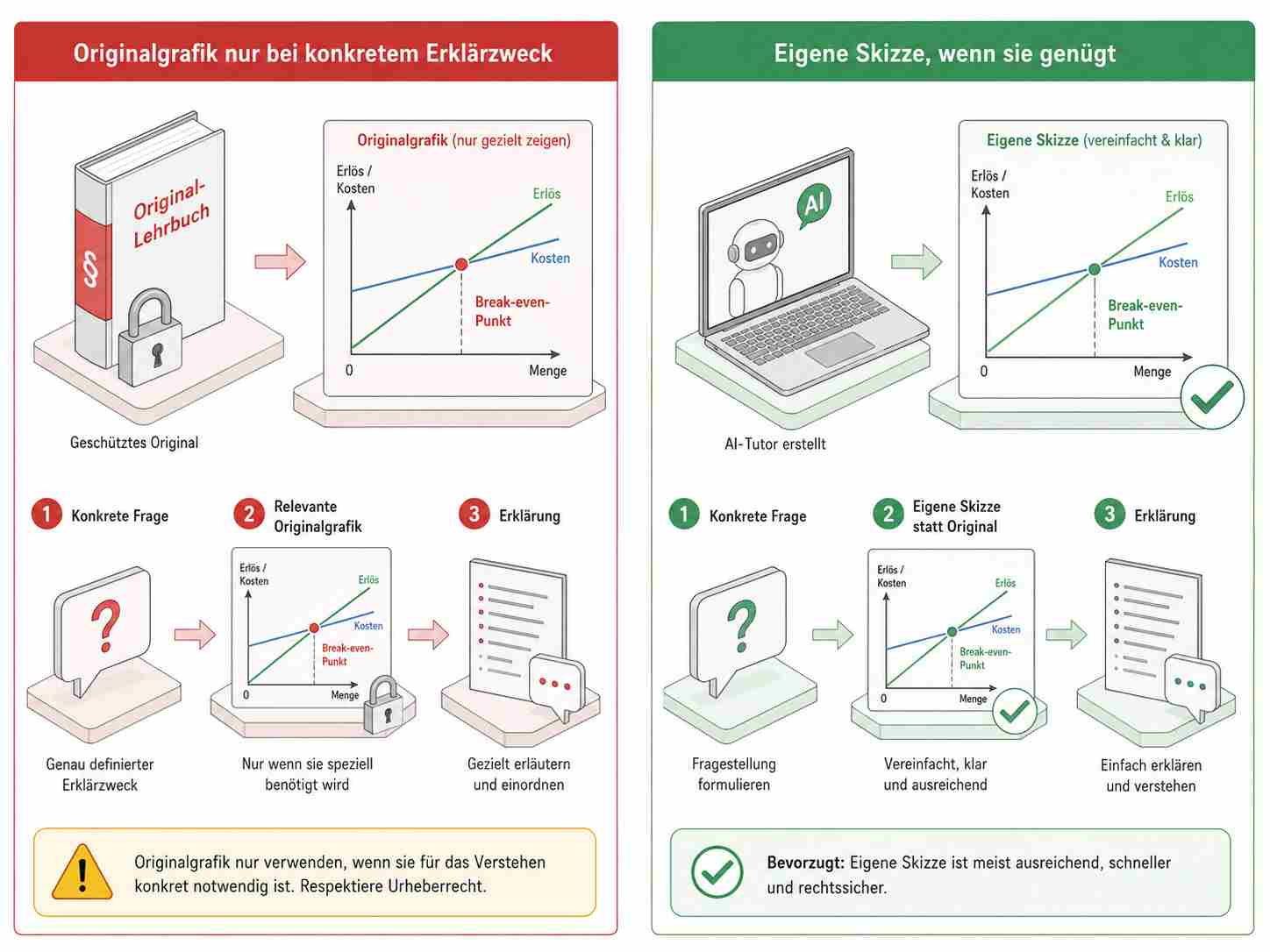
Der Teilnehmer fragt zu einer konkreten Grafik oder zu einem Konzept, das ohne Grafik schwer verständlich wäre. Das System prüft, ob die Originalgrafik für die Erklärung wirklich notwendig ist. Wenn ja, zeigt es nur die konkrete Grafik oder den notwendigen Ausschnitt, markiert relevante Elemente und erklärt sie aktiv. Wenn die Originalgrafik nicht notwendig ist, erzeugt der Tutor lieber eine eigene neue Skizze.
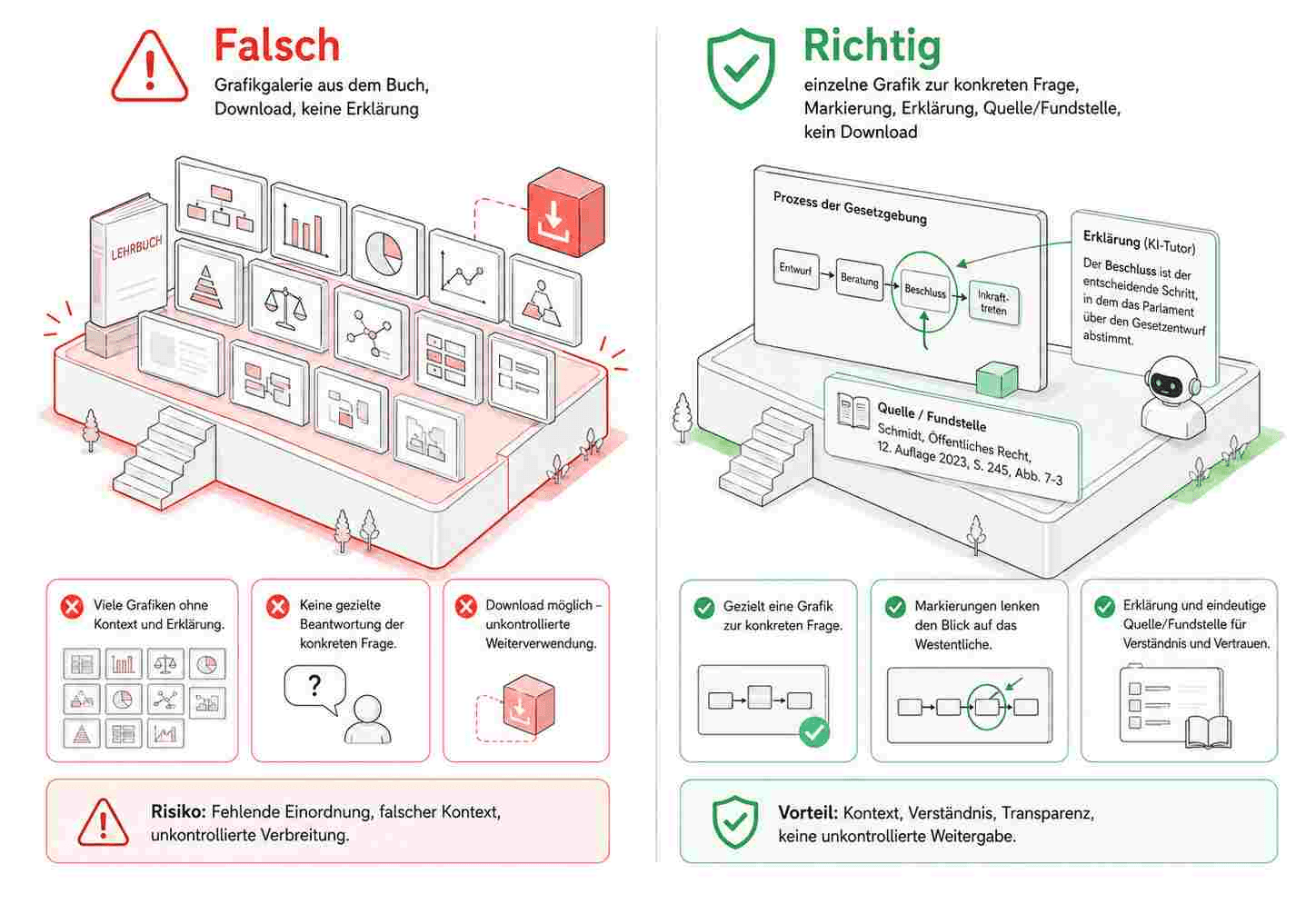
Der Unterschied ist wichtig.
Eine Grafik aus dem Buch einfach extrahieren und als Galerie anbieten: riskant.
Eine konkrete Grafik im Rahmen einer Frage anzeigen, markieren und erklären: deutlich besser begründbar, wenn ein echter Zitatzweck oder ein Unterrichtskontext vorliegt.
Eine Grafik gar nicht anzeigen, sondern nur mit eigenen Worten erklären: oft die risikoärmste Variante.
Eine eigene neue Grafik erzeugen, die denselben Zusammenhang erklärt, aber nicht die konkrete Gestaltung des Buches übernimmt: oft die didaktisch beste Variante.
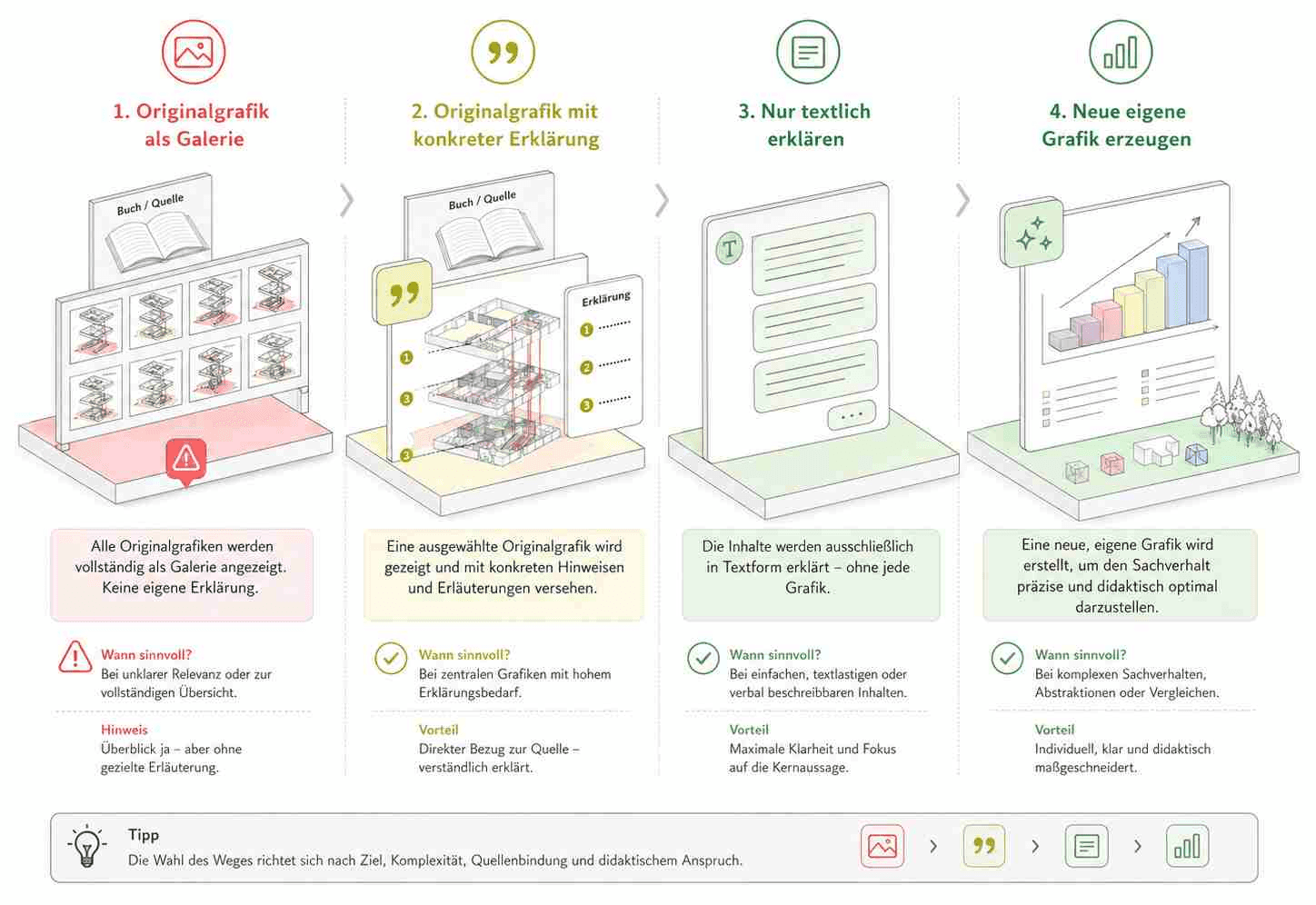
So entsteht eine einfache Produktregel:
Der KI-Tutor darf Grafiken nicht sammeln. Er darf sie erklären.
Das ist ein großer Unterschied. Bei einer Grafik zum Break-even-Point wäre eine schlechte Ausgabe: „Hier sind alle Grafiken aus dem Kapitel Kostenrechnung.“
Eine bessere Ausgabe wäre: „Du fragst nach dem Schnittpunkt in dieser Grafik. Ich zeige dir nur den relevanten Ausschnitt. Die Umsatzlinie steigt mit der Menge, die Kostenlinie beginnt wegen der Fixkosten bereits oberhalb von null. Dort, wo beide Linien sich schneiden, sind Erlöse und Kosten gleich. Ab diesem Punkt entsteht Gewinn.“
Noch besser, wenn die Originalgrafik nicht zwingend gebraucht wird: „Ich erstelle dir eine eigene vereinfachte Skizze mit denselben Grundgedanken, damit du das Prinzip verstehst.“
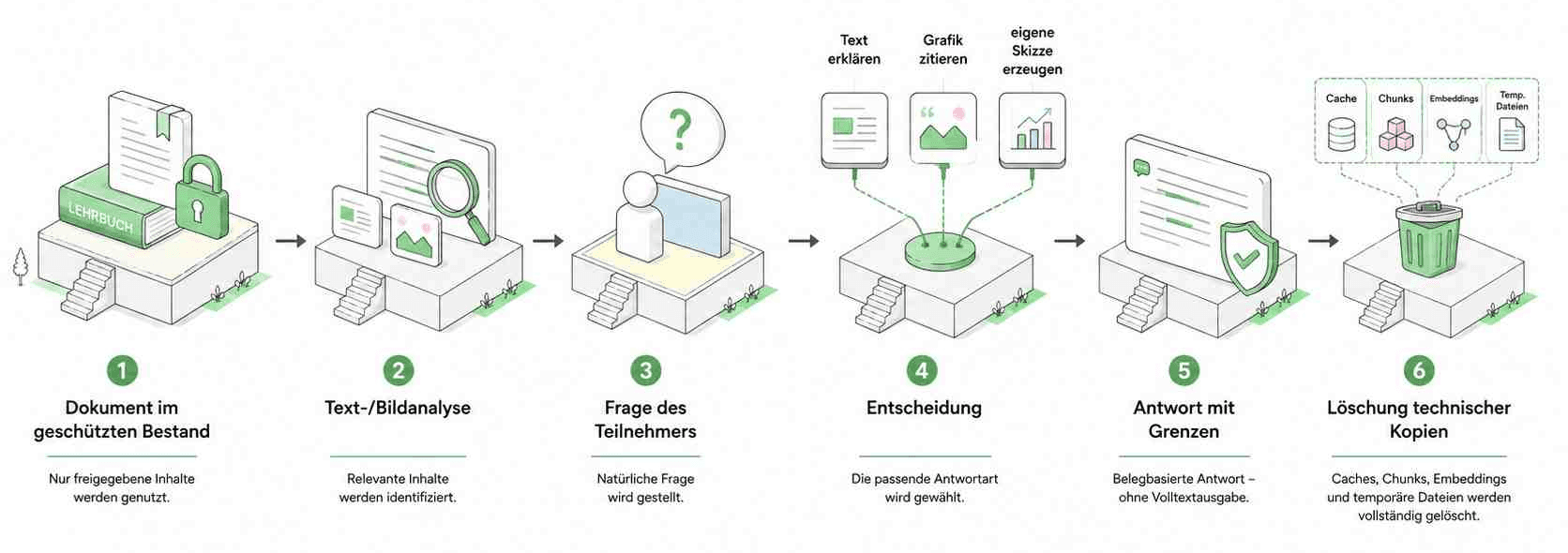
Jetzt kommt der Gesamtprozess.
Die Akademie stellt das Dokument nicht als Datei für Teilnehmer bereit. Sie nimmt es in einen geschützten Wissensbestand auf. Daraus entstehen Suchindex, Chunks und gegebenenfalls Embeddings. Der Teilnehmer sieht diese technischen Strukturen nicht. Er sieht auch nicht das Buch als Datei. Er stellt Fragen. Der Tutor antwortet mit eigenen Erklärungen. Wenn eine Grafik für das Verständnis notwendig ist, wird sie einzeln, zweckgebunden und mit Erklärung angezeigt. Wenn eine eigene Darstellung genügt, wird eine neue Darstellung erzeugt.
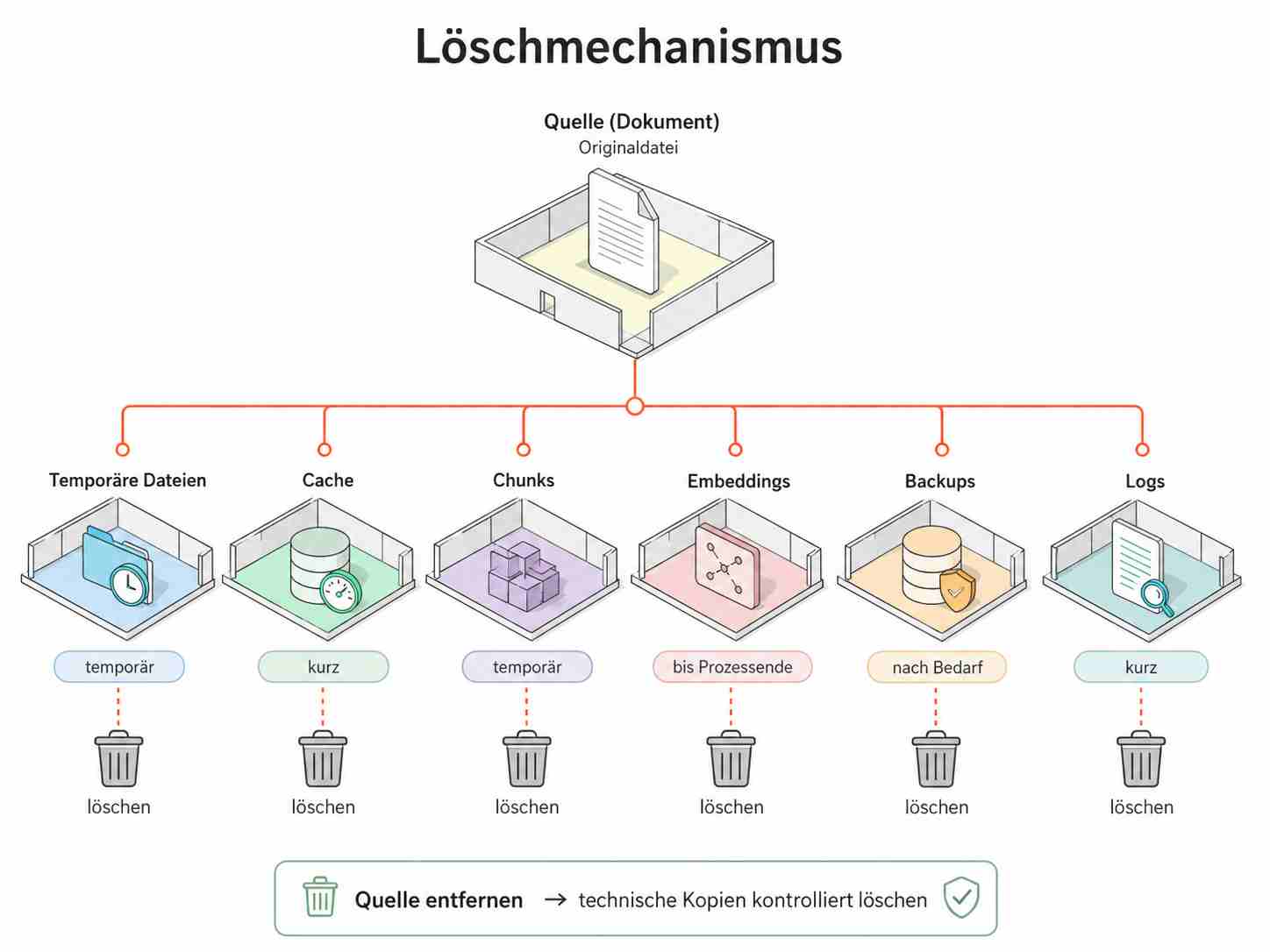
Jetzt bleibt noch der Löschmechanismus.
§ 44b UrhG verlangt, dass Vervielfältigungen zu löschen sind, wenn sie für Text und Data Mining nicht mehr erforderlich sind. Das ist nicht nur ein juristischer Satz. Das muss technisch abbildbar sein.
Temporäre Dateien werden nach der Verarbeitung gelöscht. Cache-Dateien haben kurze Lebenszeiten. Chunks werden entfernt, wenn die Quelle aus dem aktiven Wissensbestand entfernt wird. Embeddings werden versioniert und ebenfalls gelöscht, wenn die zugrunde liegende Quelle nicht mehr verwendet werden darf. Backups haben definierte Aufbewahrungsfristen und Wiederherstellungsprozesse. Logs speichern keine langen Originalpassagen. Wenn eine Quelle aus dem aktiven Wissensbestand entfernt wird, müssen die daraus erzeugten technischen Kopien kontrolliert entfernt werden können.
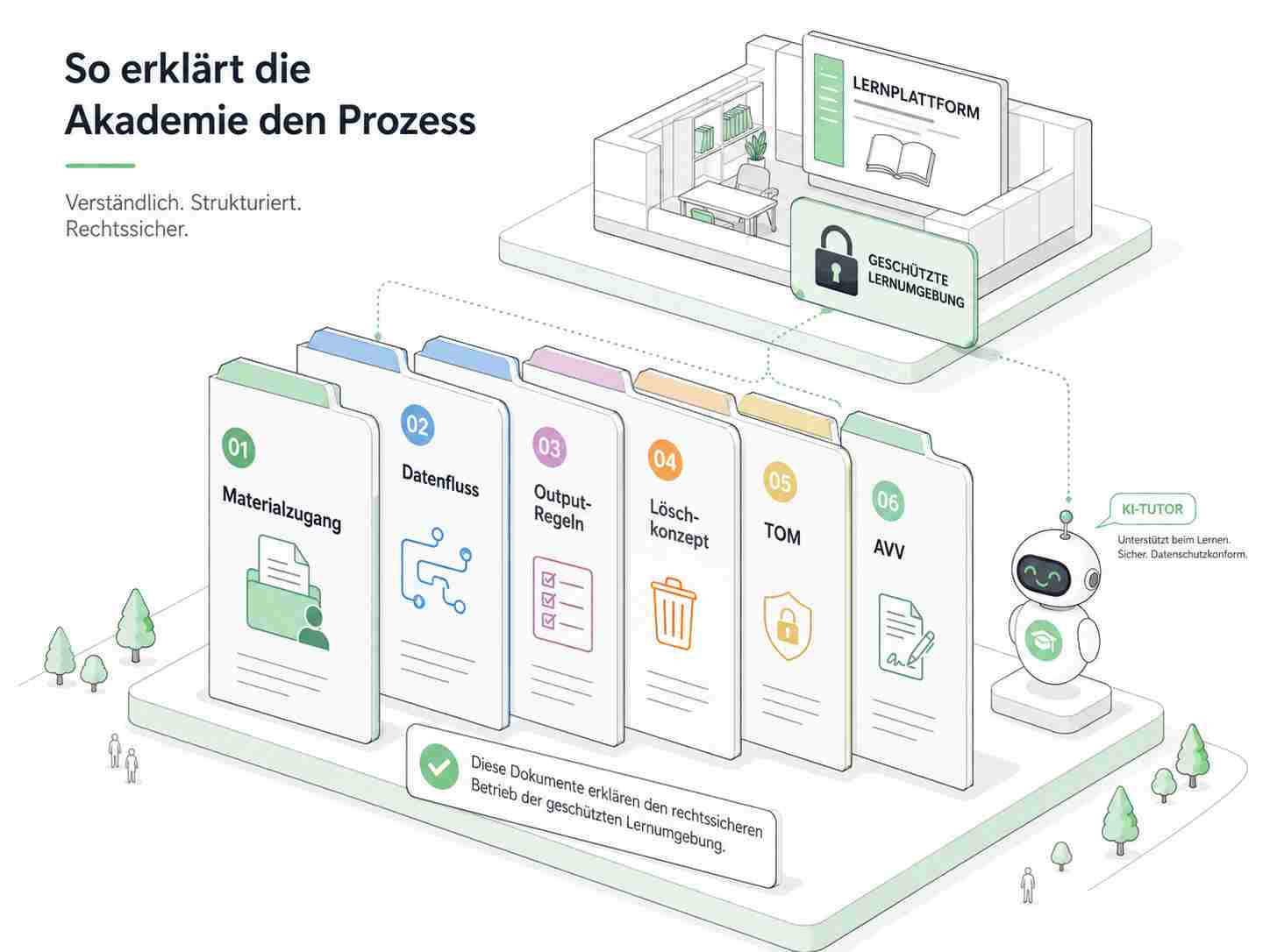
Damit der Prozess intern erklärbar bleibt, braucht eine Akademie keine Angstmappe. Aber sie braucht Unterlagen, die zeigen, dass das System kein Dokumentenordner ist.
Nicht, um zu signalisieren: „Eigentlich ist alles verboten.“
Sondern, um zeigen zu können:
Wir verteilen keine Bücher. Wir betreiben ein geschütztes Lernsystem.
Die erste Unterlage ist eine kurze Beschreibung des Materialzugangs. Darin steht nicht dramatisch „Rechtsrisiko“, sondern sachlich: Welche Dokumente befinden sich im System? Woher stammen sie? Wer darf sie im System nutzen? Werden sie als Datei angezeigt oder nur intern analysiert? Gibt es technische Schutzmaßnahmen gegen Volltextzugriff?
Die zweite Unterlage ist eine Datenflussbeschreibung. Sie zeigt, wo das Dokument liegt, welche technischen Kopien entstehen, wo Index, Chunks, Embeddings, Cache und Backups gespeichert werden und wer Zugriff hat.
Die dritte Unterlage ist eine Output-Policy. Sie beschreibt, was der Tutor darf: erklären, vergleichen, eigene Beispiele bilden, Prüfungslogik erläutern, einzelne Grafiken zweckgebunden erklären und eigene Skizzen erzeugen. Und sie beschreibt, was der Tutor nicht darf: Kapitel ausgeben, Aufgabenbanken kopieren, Tabellen rekonstruieren, das Buch zusammenfassen, Grafiken als Galerie bereitstellen oder lange Originalpassagen ausspielen.
Die vierte Unterlage ist ein Löschkonzept. Es legt fest, wie lange temporäre Dateien, Cache, Chunks, Embeddings, Logs und Backups gespeichert bleiben und wann sie entfernt werden.
Die fünfte Unterlage sind die TOM, also technische und organisatorische Maßnahmen. Dazu gehören Zugriffskontrolle, Verschlüsselung, Rollenrechte, Protokollierung, Backup-Sicherheit und regelmäßige Überprüfung. Art. 32 DSGVO verlangt ein dem Risiko angemessenes Schutzniveau und nennt unter anderem Verschlüsselung, Vertraulichkeit, Integrität, Verfügbarkeit, Belastbarkeit und regelmäßige Überprüfung der Maßnahmen.
Ein AVV, also ein Auftragsverarbeitungsvertrag, wird relevant, wenn ein externer Dienstleister personenbezogene Daten im Auftrag verarbeitet, etwa Teilnehmerfragen, Nutzerkennungen oder Lernfortschritte. Art. 28 DSGVO verlangt in solchen Fällen einen Vertrag oder ein anderes Rechtsinstrument, das unter anderem Gegenstand, Dauer, Art und Zweck der Verarbeitung sowie Pflichten und Rechte festlegt.
Die finale Aussage ist deshalb nicht:
„Wir laden Lehrbücher einfach in KI hoch.“
Sondern:
Wir stellen Lehrbücher nicht als Dateien bereit. Wir nutzen rechtmäßig zugängliche Dokumente in einem geschützten System zur Suche, Analyse und Erklärung. Technische Kopien entstehen nur im notwendigen Rahmen. Teilnehmer erhalten keine Volltextzugriffe, sondern eigenständige Erklärungen. Grafiken werden nur dann gezeigt, wenn sie für die konkrete Erklärung erforderlich sind — nicht als Bildersammlung. Nicht mehr erforderliche technische Kopien werden gelöscht.
Das ist der Unterschied zwischen einem riskanten Dokumentenordner und einem professionellen KI-Tutor.
Ein Mensch darf lesen, verstehen und erklären. Ein KI-Tutor kann diesen didaktischen Prozess unterstützen, wenn er nicht das Buch verteilt, sondern Wissen erschließt: mit geschütztem Zugriff, begrenzter Ausgabe, sauberem Umgang mit Grafiken, nachvollziehbarem Löschmechanismus und klaren Regeln gegen Buchersatz.





