In vielen Lernumgebungen funktioniert Üben noch nach einem einfachen Muster: Alle bekommen dieselbe Anzahl an Aufgaben, oft in derselben Reihenfolge, und mehrere Versuche sind erlaubt. Dieses Vorgehen ist organisatorisch leicht umzusetzen. Für die Messung von Lernen hat es aber erkennbare Grenzen. Die Forschung zu klassischer Testtheorie, Übungseffekten und adaptivem Testen zeigt drei typische Probleme: Erstens sagt die bloße Anzahl richtiger Antworten wenig darüber aus, wie schwierig diese Antworten waren. Zweitens erzeugt wiederholte Konfrontation mit denselben oder sehr ähnlichen Aufgaben sogenannte Practice Effects, also Leistungssteigerungen durch Gewöhnung oder Wiedererkennen statt durch echten Kompetenzzuwachs. Drittens ist ein festes Set von Aufgaben nicht für alle Lernenden gleich präzise: Für manche ist es zu leicht, für andere zu schwer. Adaptive Verfahren wurden gerade entwickelt, um diese Unterschiede besser aufzufangen.

Ein einfaches Beispiel zeigt das Problem. Zwei Personen erreichen jeweils 6 von 10 Punkten. Auf den ersten Blick wirken beide gleich stark. In Wirklichkeit kann Person A sechs anspruchsvolle Fallaufgaben gelöst haben, während Person B sechs reine Erinnerungsfragen beantwortet hat. Die Rohpunktzahl ist gleich, die gezeigte Kompetenz aber nicht zwingend. Genau deshalb reicht „richtig oder falsch zusammenzählen“ in der Aus-, Fort- und Weiterbildung oft nicht aus, wenn Lernstände fair eingeordnet und nächste Lernschritte passend gewählt werden sollen.
Ein zweites Beispiel betrifft Mehrfachversuche. Wenn eine lernende Person dieselbe Aufgabe mehrmals sieht, kann sie sich an Formulierungen, Antwortmuster oder Ausschlussstrategien erinnern. Der Score steigt dann zwar, aber nicht immer, weil das zugrunde liegende Verständnis gewachsen ist. In der Forschung werden solche Verbesserungen durch Wiederholung als Practice Effects beschrieben. Genau deshalb gilt Wiedererkennung allein nicht als verlässlicher Nachweis von Kompetenzentwicklung.
Für die Weiterbildung ist das besonders relevant. In Aus-, Fort- und Weiterbildung sind Gruppen oft heterogen: Manche steigen mit viel Vorwissen ein, andere brauchen mehr Grundlagen, wieder andere können Wissen zwar wiedergeben, aber noch nicht sicher anwenden. Studien zu adaptivem Lernen und adaptiver Aufgabenauswahl zeigen, dass feste Übungspläne und starre Testlängen für solche Unterschiede oft nicht optimal sind. Verfahren, die sich laufend an einzelne Personen und einzelne Inhalte anpassen, können Lernen und Messung effizienter machen als feste Schemata.
Was Item Response Theory anders macht
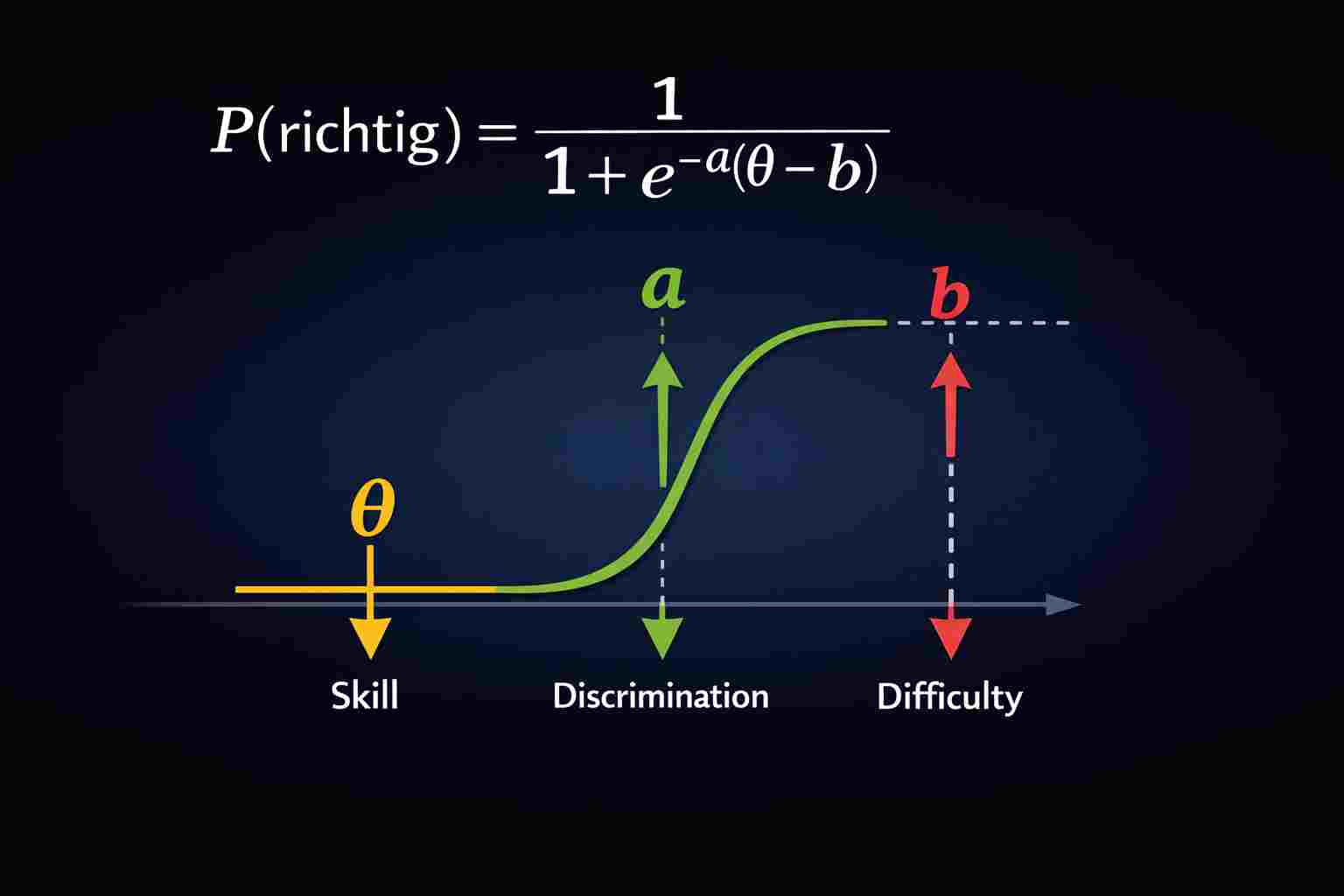
Genau hier setzt die Item Response Theory, kurz IRT, an. IRT ist eine mathematische Theorie, die nicht nur fragt, ob eine Antwort richtig war, sondern auch, wie wahrscheinlich diese richtige Antwort angesichts der aktuellen Fähigkeit einer Person und der Schwierigkeit der Aufgabe war. Vereinfacht gesagt: IRT betrachtet die Leistung immer als Beziehung zwischen Person und Aufgabe. Eine richtige Antwort auf eine schwere Aufgabe zählt daher anders als eine richtige Antwort auf eine leichte Aufgabe.
Der zentrale IRT-Gedanke lässt sich mit einer einfachen Formel ausdrücken:
„Beobachtung“ ist hier zum Beispiel 1 für richtig und 0 für falsch. „Lernrate“ beschreibt, wie stark der Wert nach einer Antwort angepasst wird. Ein Beispiel: Wenn das System nur 20 Prozent Erfolgschance erwartet, die Person aber richtig antwortet, steigt der Wert deutlich. Wenn das System schon 90 Prozent Erfolgschance erwartet und die Person richtig antwortet, fällt der Anstieg kleiner aus. So werden überraschende Leistungen stärker berücksichtigt als erwartbare Ergebnisse. Diese Logik ist mit IRT und Elo-ähnlichen Online-Updates gut vereinbar.
Für Lernplattformen hat das einen praktischen Nutzen: Es wird schwerer, allein durch Glück oder reines Wiederholen künstlich sehr hohe Werte zu erreichen. Wenn ein System immer nur dieselbe Frage wiederholt, entstehen leicht Wiedererkennungseffekte. Wenn es dagegen neue, thematisch passende Aufgaben generiert oder auswählt und die Bewertung an erwartete Wahrscheinlichkeit koppelt, wird Fortschritt robuster gemessen. Adaptive Itemauswahl kann Practice Effects zwar nicht vollständig beseitigen, aber sie kann wiederholte Exposition gegenüber identischen Items verringern und damit die Aussagekraft verbessern.
Dabei steht θ für die Fähigkeit einer Person, b für die Schwierigkeit der Aufgabe und aaa für die Trennschärfe. Die Formel sagt: Je höher die Fähigkeit im Vergleich zur Schwierigkeit ist, desto größer ist die Wahrscheinlichkeit einer richtigen Antwort. Wenn Fähigkeit und Schwierigkeit ungefähr gleich hoch sind, liegt die Erfolgswahrscheinlichkeit im einfachen Modell bei etwa 50 Prozent.
Der Begriff Schwierigkeit ist noch recht anschaulich. Eine leichte Aufgabe zum Thema Buchhaltung könnte lauten: „Nennen Sie den Zweck einer Rechnung.“ Eine schwierigere Aufgabe könnte lauten: „Beurteilen Sie einen konkreten Rechnungsfall mit mehreren Positionen und entscheiden Sie, ob die Angaben vollständig und korrekt sind.“ In IRT bedeutet Schwierigkeit also: Wie viel Fähigkeit braucht man typischerweise, um diese Aufgabe mit guter Wahrscheinlichkeit zu lösen?
Der Begriff Trennschärfe ist technischer und sollte immer mit einem Beispiel erklärt werden. Trennschärfe beschreibt, wie gut eine Aufgabe Lernende mit etwas niedrigerem und etwas höherem Kompetenzniveau voneinander unterscheidet. Ein Beispiel: Die Frage „Wofür steht die Abkürzung USt?“ ist für viele Lernende so leicht, dass fast alle sie richtig beantworten. Diese Aufgabe trennt kaum zwischen „gerade verstanden“ und „wirklich sicher beherrscht“. Eine Fallaufgabe wie „Prüfen Sie in diesem Beispiel, ob Umsatzsteuer korrekt ausgewiesen wurde, und begründen Sie Ihre Entscheidung“ kann viel besser zeigen, wer das Thema wirklich verstanden hat. Eine solche Aufgabe hat typischerweise eine höhere Trennschärfe, weil kleine Fähigkeitsunterschiede hier sichtbarer werden. In 2PL-Modellen wird genau dieser Unterschied über den Parameter aaa abgebildet: Je steiler die Kurve, desto stärker trennt das Item.
Warum ist IRT für adaptives Lernen so wichtig? Weil IRT nicht nur eine Note am Ende liefert, sondern eine laufende Schätzung darüber, wo eine Person auf einem Thema gerade steht. Ein adaptives System kann damit die nächste Aufgabe gezielter wählen. Zu leichte Aufgaben liefern wenig neue Information. Zu schwere Aufgaben oft ebenfalls, weil ein Fehler dort kaum überrascht. Besonders informativ sind Aufgaben, die ungefähr zum aktuellen Lernstand passen. Genau deshalb erreichen adaptive Tests oft mit weniger Aufgaben eine hohe Messgenauigkeit als feste Tests mit derselben Länge.
Das löst ein Kernproblem klassischer Übungslogiken. Wenn alle immer dieselbe Anzahl an Übungen bekommen, wird die Messung ungleich präzise. Für sehr starke Lernende sind viele Aufgaben zu leicht; für sehr schwache Lernende sind viele Aufgaben zu schwer. IRT-basierte oder IRT-inspirierte Systeme können dagegen Aufgaben so auswählen, dass sie für die jeweilige Person aussagekräftig bleiben. Das ist nicht nur für Prüfungen nützlich, sondern auch für Lernbegleitung: Das System kann besser entscheiden, ob als Nächstes wiederholt, erklärt oder anspruchsvoller geübt werden sollte.
In der beruflichen Bildung kommt noch ein zweiter wichtiger Punkt hinzu: Taxonomiestufe ist nicht dasselbe wie Schwierigkeit. In IHK- und DIHK-nahen Rahmenplänen werden Lernziele häufig nach Anwendungstaxonomie beschrieben. Dort wird zwischen Wissen, Verstehen und Anwenden unterschieden. „Wissen“ meint den Erwerb und Nachweis von Kenntnissen, „Verstehen“ das Erkennen von Zusammenhängen, und „Anwenden“ die Fähigkeit zu sach- und fachgerechtem Handeln auf Basis dieses Verständnisses.
Ein Beispiel macht den Unterschied klar. Nehmen wir das Thema Datenschutz.
Auf Wissen-Ebene könnte eine Frage lauten: „Nennen Sie drei Grundprinzipien der Datenverarbeitung.“
Auf Verstehen-Ebene: „Erläutern Sie, warum das Prinzip der Zweckbindung für Unternehmen wichtig ist.“
Auf Anwenden-Ebene: „Beurteilen Sie diesen Fall aus dem Arbeitsalltag und entscheiden Sie, ob die geplante Datenverarbeitung zulässig ist.
Die Taxonomiestufe beschreibt also die Art der geistigen Leistung. Schwierigkeit beschreibt dagegen, wie anspruchsvoll die konkrete Aufgabe innerhalb dieser Art ist. Eine Anwenden-Aufgabe kann leicht sein, wenn sie sich eng an ein bekanntes Muster anlehnt. Eine Wissen-Aufgabe kann schwer sein, wenn sie seltene Details oder Ausnahmen abfragt. Taxonomie und Schwierigkeit dürfen deshalb nicht verwechselt werden.
Für adaptive Lernsysteme ist diese Unterscheidung sehr wertvoll. Ein System kann dieselbe Thematik auf unterschiedlichen Taxonomiestufen prüfen und zusätzlich die Schwierigkeit variieren. So lässt sich nicht nur feststellen, ob jemand ein Thema schon kennt, sondern auch, auf welcher Tiefe es beherrscht wird. In der Aus- und Weiterbildung ist das besonders nützlich, weil berufliche Handlungskompetenz meist nicht beim Erinnern endet, sondern beim Verstehen und Anwenden sichtbar werden soll.
Ein weiterer Vorteil von IRT ist, dass Fortschritt dynamisch bewertet werden kann. Dafür nutzt man neben der Wahrscheinlichkeitsformel oft eine Update-Regel. Die Idee ist einfach: Das System vergleicht, was es erwartet hat, mit dem, was tatsächlich passiert ist. Eine einfache Form lautet:

„Beobachtung“ ist hier zum Beispiel 1 für richtig und 0 für falsch. „Lernrate“ beschreibt, wie stark der Wert nach einer Antwort angepasst wird. Ein Beispiel: Wenn das System nur 20 Prozent Erfolgschance erwartet, die Person aber richtig antwortet, steigt der Wert deutlich. Wenn das System schon 90 Prozent Erfolgschance erwartet und die Person richtig antwortet, fällt der Anstieg kleiner aus. So werden überraschende Leistungen stärker berücksichtigt als erwartbare Ergebnisse. Diese Logik ist mit IRT und Elo-ähnlichen Online-Updates gut vereinbar.
Für Lernplattformen hat das einen praktischen Nutzen: Es wird schwerer, allein durch Glück oder reines Wiederholen künstlich sehr hohe Werte zu erreichen. Wenn ein System immer nur dieselbe Frage wiederholt, entstehen leicht Wiedererkennungseffekte. Wenn es dagegen neue, thematisch passende Aufgaben generiert oder auswählt und die Bewertung an erwartete Wahrscheinlichkeit koppelt, wird Fortschritt robuster gemessen. Adaptive Itemauswahl kann Practice Effects zwar nicht vollständig beseitigen, aber sie kann wiederholte Exposition gegenüber identischen Items verringern und damit die Aussagekraft verbessern.
Wissenschaftlich wichtig ist aber auch die Grenze der Theorie. Klassisches Computerized Adaptive Testing arbeitet normalerweise mit einer vorkalibrierten Aufgabenbank. Die Schwierigkeit und weitere Parameter der Aufgaben wurden also vorher statistisch geschätzt. Moderne Lernsysteme, die Aufgaben dynamisch erzeugen, arbeiten deshalb oft nicht als „klassisches IRT-System“ im engen Sinn, sondern eher als IRT-inspirierte adaptive Logik. Das ist kein Nachteil, solange sauber getrennt wird zwischen der allgemeinen Theorie und der konkreten technischen Umsetzung.
Wie adaptive Lernsysteme IRT praktisch nutzen
An dieser Stelle eignet sich Tarsus als Beispiel für eine praktische Umsetzung. Öffentlich beschreibt Tarsus seinen Lerncoach als System, das auf den Unterlagen der jeweiligen Organisation arbeitet, Lernende im eigenen Tempo trainiert, Fortschritt dokumentiert und mithilfe von Machine Learning, didaktischen Regeln und Sprachmodellen den nächsten Übungsschritt vorhersagt. In den Praxiswissen-Beiträgen wird außerdem betont, dass Mini-Übungen, Feedback und Wissenschecks situativ im Dialog entstehen und nicht nur als vorproduzierte Standardbausteine vorliegen.
Tarsus nutzt diese Logik in einer eigenen Form: Das System geht ein Dokument Thema für Thema und Seite für Seite durch, erzeugt Fragen auf unterschiedlichen Taxonomiestufen und in drei Schwierigkeitsbereichen – einfach, mittel und schwer. Die nächste Frage hängt nicht nur davon ab, ob die vorige Antwort richtig oder falsch war, sondern auch davon, wie gut sie ausfiel und wie hoch die erwartete Wahrscheinlichkeit war. Ein Themenwert zwischen 0 und 1 dient dabei als laufende Schätzung des aktuellen Könnens in genau diesem Themenbereich. Zusätzlich fließen Taxonomiestufe, Verlauf, Lernrate und frühere Antworten ein. Diese Detailbeschreibung stammt aus deinen internen Hinweisen; öffentlich dokumentiert sind vor allem die adaptive Grundidee und die dialogische Erzeugung der Übungen. Mit der allgemeinen IRT-Logik ist diese Oberfläche aber gut vereinbar.
Ein Beispiel: Eine lernende Person beantwortet eine Verstehen-Frage zu einem Thema sehr sicher. Dann kann das System im selben Thema auf eine Anwenden-Frage wechseln oder innerhalb derselben Taxonomiestufe die Schwierigkeit erhöhen. Antwortet die Person auf eine Anwenden-Frage unsicher oder nur teilweise richtig, kann das System zurück auf eine einfachere Aufgabe gehen, ohne das Thema komplett zu verlassen. So wird nicht einfach „mehr vom Gleichen“ geübt, sondern gezielt das, was für den nächsten Schritt informativ ist. Das ist der pädagogische Mehrwert einer IRT-inspirierten Logik: Sie verbindet Bewertung und Aufgabensteuerung.
Gerade im Kontext von AZAV, Bildungsgutschein oder Qualifizierungsgeld ist das methodisch interessant, auch wenn IRT selbst natürlich kein Förderkriterium ist. Die Bundesagentur für Arbeit knüpft Förderung an rechtliche und organisatorische Voraussetzungen wie Zulassung, Umfang und Förderzweck. Ein adaptives System kann diese Förderung nicht ersetzen. Es kann aber individuelle Lernbegleitung, nachvollziehbare Progression und dokumentierten Kompetenzaufbau methodisch unterstützen. Für Weiterbildungskontexte, in denen Lernstände sichtbar gemacht und Fortschritte begründet werden sollen, ist das ein klarer Vorteil.
Zusammengefasst
Item Response Theory ist vor allem deshalb wichtig, weil sie Lernen nicht als bloßes Zählen richtiger Antworten versteht. Sie fragt, wie schwierig eine Aufgabe war, wie wahrscheinlich eine richtige Antwort war und welche Aufgabe als Nächstes den größten Erkenntniswert hat. Für Aus-, Fort- und Weiterbildung ist das besonders relevant, weil dort sehr unterschiedliche Lernstände, Lerntempi und Zielniveaus zusammenkommen. Feste Übungssets mit mehreren Wiederholungen sind einfach zu organisieren, aber sie messen Fortschritt nur begrenzt präzise. IRT und adaptive Lernlogiken bieten hier eine wissenschaftlich gut begründete Alternative: fairere Einordnung, passendere nächste Aufgaben und eine deutlich bessere Trennung zwischen Wiedererkennen und echtem Kompetenzzuwachs.





